
What is Data Drift and How to Detect it in Machine Learning?

As machine learning models are deployed in production environments, it is essential to monitor their performance and detect any changes that might affect their accuracy. One of the most common issues that can affect the performance of machine learning models is data drift. Data drift refers to the change in the distribution of input data over time, which can cause the model's performance to degrade. In this article, we will discuss data drift, its causes, and how to detect it in real-time datasets.
What is Data Drift?
Data drift is a common issue that occurs when the statistical properties of the input data change over time. It can be caused by various factors, such as changes in user behavior, seasonal patterns, or changes in the data collection process. Data drift can affect the performance of machine learning models, as they are trained on a specific dataset and might not generalize well to new data. For example, let's say you have a machine learning model that predicts the price of a house based on its features, such as the number of bedrooms, bathrooms, and square footage. If the distribution of the input features changes over time, such as the average size of houses increasing, the model's performance might degrade, as it was trained on a different distribution of input features.
Causes of Data DriftData drift can be caused by various factors, such as:
Changes in user behavior: User behavior can change over time, leading to changes in the distribution of input data. For example, if you have a recommendation system that recommends products to users based on their purchase history, changes in user behavior, such as a shift in preferences, can affect the distribution of input data.
Seasonal patterns: Seasonal patterns can affect the distribution of input data, leading to data drift. For example, if you have a demand forecasting model that predicts the sales of a product, seasonal patterns, such as holidays or weather changes, can affect the distribution of input data.
Changes in the data collection process: Changes in the data collection process, such as new data sources or changes in data preprocessing, can affect the distribution of input data, leading to data drift.
Detecting Data Drift
To detect data drift, you need to monitor the distribution of input features and compare them with the distribution of the training data. If there is a significant difference, it might indicate data drift. There are various ways to detect data drift, such as statistical tests, model-based methods, and time distribution-based methods.
Statistical tests: Statistical tests, such as the Kolmogorov-Smirnov (KS) test or the Mann-Whitney U test, can be used to compare the distribution of input features between the training data and new data. If the p-value of the statistical test is less than a predefined significance level, it might indicate data drift.
Model-based methods: Model-based methods use the difference between the model's predictions on the training data and new data to detect data drift. For example, you can use the difference between the model's accuracy on the training data and new data to detect data drift.
Time distribution-based methods: Time distribution-based methods monitor the distribution of input features over time and detect changes that might indicate data drift. For example, you can use time-series analysis to detect changes in the distribution of input features over time.
Real-Time Data Drift Detection
There are various tools and techniques that you can use to detect data drift in real-time datasets, such as:
Azure Machine Learning: Azure Machine Learning provides a data drift detection feature that can monitor datasets and produce metrics by profiling new data in the time series dataset. The feature can detect data drift for various input features, such as numerical, categorical, and text data.
Eurybia: Eurybia is an open-source Python library that provides performance metrics for data drift, such as AUC of the "data drift classifier" and Jensen Shannon Divergence of the predicted probabilities distributions, which allows tracking over time.
DeepChecks: DeepChecks is a Python library that provides various checks for data and model drift, including drift detection for tabular data. The library can detect data drift for various input features, such as numerical, categorical, and text data.
Example of Data Drift Detection
Here's an example of how to detect data drift in datasets using Python. In this example, we will use the famous Iris dataset to demonstrate how to detect data drift.
import pandas as pd
import numpy as np
from scipy.stats import ks_2samp
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
# Split the dataset into training data and new data
train_data = iris_df.sample(frac=0.7, random_state=42)
new_data = iris_df.drop(train_data.index)
# Set a significance level
alpha = 0.05
# Perform the Kolmogorov-Smirnov test for each feature
for feature in iris_df.columns:
ks_statistic, p_value = ks_2samp(train_data[feature], new_data[feature])
print(f"Feature: {feature}")
if p_value < alpha:
print("Data drift detected. The distributions are significantly different.")
else:
print("No data drift detected. The distributions are not significantly different.")
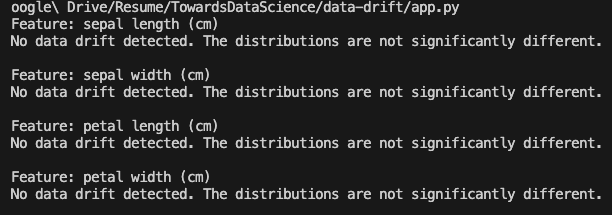
print()In this example, we use the Iris dataset from the sklearn.datasets module. We split the dataset into train_data and new_data to simulate the training data and new data. Then, we perform the Kolmogorov-Smirnov test for each feature in the dataset to detect data drift.
Here is an outcome derived from analyzing the given dataset.
Conclusion
Data drift is a common issue that can affect the performance of machine learning models in production environments. To detect data drift, you need to monitor the distribution of input features and compare them with the distribution of the training data. In real-world scenarios, you need to detect data drift in real-time datasets to monitor the performance of machine learning models effectively. There are various tools and techniques that you can use to detect data drift in real-time datasets, such as Azure Machine Learning, Eurybia, and DeepChecks.